
Verifique seu ambiente de produção com o Health Checking do Spring Boot Actuator
Aprenda a escrever health checks no Spring Boot usando o Actuator


No post anterior mostrei a você o que é o Actuator, seus principais recursos e, muito importante: como garantir que ele não se torne uma falha de segurança. Agora apresento aquele que é meu recurso favorito nesta ferramenta: o health checking.
O objetivo aqui é não só te mostrar como tirar proveito deste recurso a partir da implementação dos seus próprios indicadores, mas também contar alguns usos que faço do recurso que talvez possam lhe ser úteis.
O que é o Health Checking
Como o próprio nome já diz, o health checking nos permite verificar a qualidade do serviço que implantamos: pense nesta parte do Actuator como aquela responsável pro realizar os testes que verificam se não há alguma condição que esteja degradando ou mesmo impossibilitando a execução dos seus serviços. Vamos a alguns exemplos rápidos de health checking:
- Verificar se há espaço em disco suficiente para a execução do seu código.
- Checar se outros serviços que sua aplicação precisa acessar estão acessíveis.
- No caso de novas implantações, verificar se todas as condições para o requisito que você implementou estão de acordo.
- Checar se é possível acessar o banco de dados.
Resumindo: qualquer verificação que você precise fazer relativas às condições que sua plataforma deve atender para que funcione corretamente.
Este é um post mais prático pois o principal conceito que você precisa ter em mente acabei de te dar.
Primeiro contato e configurações de segurança
Se você já incluiu o Actuator em seu projeto tal como descrito no post anterior e acessou o endpoint /actuator/health você verá a seguinte saída que é bem sem graça:
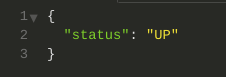
É possível ter uma saída bem mais detalhada mas, como sempre, você precisa ter segurança em mente.
Segurança

Pode parecer estranho: no post anterior nós vimos como limitar o acesso ao Actuator, mas mesmo assim há algumas questões de segurança que você deve levar em consideração ao expor os detalhes de health checking do seu sistema.
O feedback que recebemos agora há pouco nos mostrou que o sistema está ok (por isto o “UP”), mas quais verificações foram feitas? Será que é possível obter um detalhamento maior? Yeap! Entra a próxima chave de configuração management.endpoint.health.show-details que pode receber os seguintes valores:

Você define quais as permissões que o usuário precisa ter para acessar os detalhes do health checking usando a configuração management.endpoint.health.roles, tal como no exemplo a seguir, no qual apenas usuários com a permissão ROLE_ADMIN tem acesso ao detalhamento:
management.endpoint.health.roles=ROLE_ADMINCom todas as condições satisfeitas, você agora obtém um detalhamenteo bem melhor ao acessar o endpoint /actuator/health:
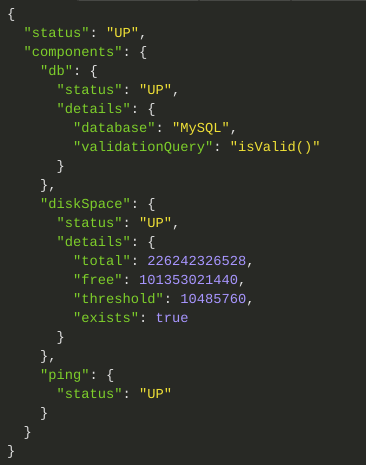
Bem mais legal, hein? Podemos ver aqui três componentes, que na realidade são três health checkings: db, que verifica se conseguimos obter uma conexão válida com o banco de dados, diskSpace, que verifica o espaço livre em disco e, finalmente, ping que, bom, é apenas um ping ao sistema.
Mais um pequeno detalhe de segurança: evitar um DoS acidental
Segurança vai além de evitar expor dados para quem não deve ter acesso. Alguns testes que você executa podem ser caros do ponto de vista computacional. Sendo assim, caso sejam executados diversas vezes em um curto espaço de tempo podem prejudicar a qualidade de serviço do seu sistema.
O Actuator pode cachear as respostas dos endpoints disponibilizados: com isto você evita o reprocessamento desnecessário dos mesmos e, consequentemente, evita uma série de problemas caso o processamento destes endpoints seja caro do ponto de vista computacional. Esta configuração é por endpoint, e no caso do “/health” a chave de configuração é management.endpoint.health.cache.time-to-live.
O valor default desta configuração é “0ms”, ou seja, não há cacheamento. Aumente este valor para algo tipo “5000ms” para que haja um cacheamento de 5 segundos, por exemplo. Faça isto se achar interessante: eu acho.
Como nascem os testes?

Após habilitarmos a apresentação do detalhamento do health checking obtivemos a seguinte saída:
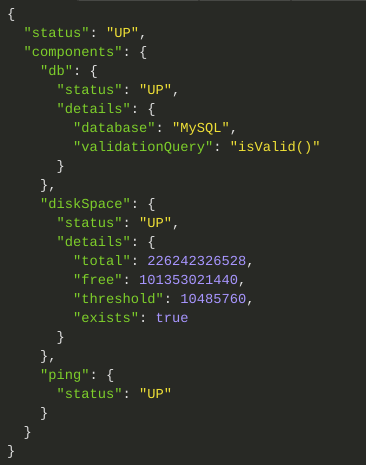
Nós não escrevemos os componentes db, diskSpace ou ping. De onde vieram? Isto é algo legal no ecossistema Spring Boot: os autores de módulos como o JPA, por exemplo, escrevem seus próprios testes, que automaticamente são disponibilizados ao Actuator do Spring Boot usando a funcionalidade de auto configuração do framework. A maioria dos módulos (quase todos mesmo) oferecem isto para você de graça, tais como o Redis, JPA, Sessions, etc.
E, claro, nós vamos ver aqui também como escrever os nossos próprios testes também, né? Ou melhor: “Health Indicators”.
Um Health Indicator para chamar de seu
Usei o termo “teste” até agora por razões estritamente didáticas. Não é o nome correto: o ideal é “Health Indicator”, por que é isto que eles realmente são: indicadores. Eles é que nos dizem se a condição está ou não satisfeita e, também, os detalhes que indicam o quê pode estar errado.
Para começar vamos escrever um health indicator bem simples, que apenas verifique a existência ou não de um arquivo em nosso sistema de arquivos. Vamos ao código:

Tudo o que você precisa fazer neste nosso primeiro indicador é criar um bean do Spring que implemente a interface org.springframework.boot.actuate.health.HealthIndicator. Observe que precisamos implementar um único método chamado health que retorna um objeto do tipo… Health.
A classe Health é um builder (leia o javadoc aqui) que é bem fácil de ser usado como pode ser visto no nosso exemplo. Essencialmente você pode ter os seguintes valores para o seu indicador de saúde:

Neste link você encontra o Javadoc com a descrição detalhada de todos os estados. Na prática só uso UP e DOWN: são mais que suficientes para a esmagadora maioria das coisas que preciso.
Voltemos ao nosso indicador. Acessando novamente o endpoint /actuator/health temos a seguinte saída:
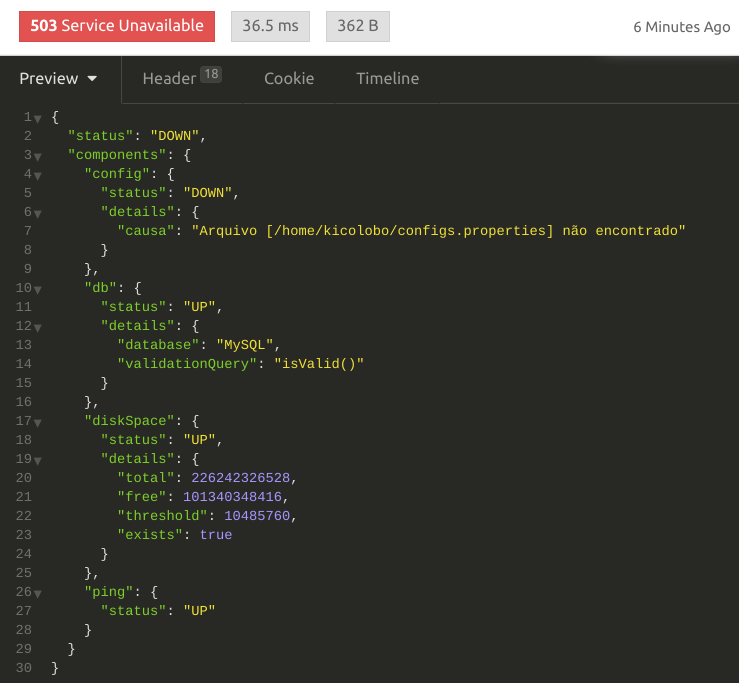
Observe alguns detalhes importantes:
- O código HTTP da requisição é 503 – Service Unavailable. Com isto sua ferramenta de monitoramento favorita pode te avisar de forma automatizada que algo não está ok.
- Observe que no detalhamento do erro incluí uma chave chamada “causa”, cujo texto é a mensagem informando qual o problema que encontrei.
- O nome do componente é o nome do nosso bean Spring: config.
Voltando ao nosso código fonte, você pode incluir quantas chaves de informação quiser em seu erro, o que possibilita expor todos os problemas encontrados em seu indicador. Quando crio o arquivo esperado, o sistema volta ao estado normal:
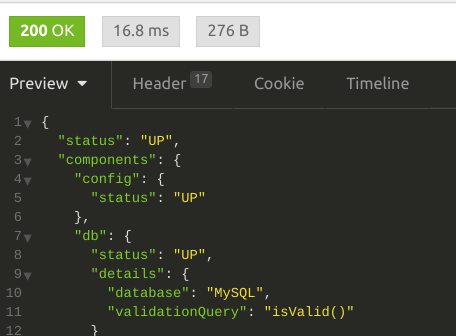
Observe que se quiser, você pode incluir detalhes na mensagem de sucesso também, veja como customizei a saída de nosso indicador:
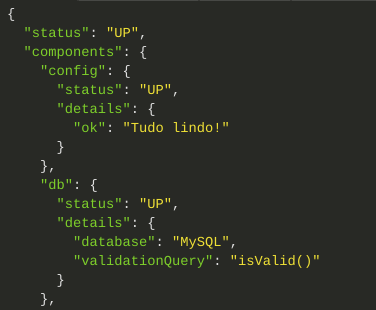
Como exercício, usando o exemplo de código que apresentei acima, descubra como inclui o detalhamento da imagem acima.
Agrupadores
Talvez você queira organizar os health indicators em grupos. Um grupo, por exemplo, contendo todos os indicadores de persistência. Nunca precisei desta funcionalidade mas acho que pode ser interessante para alguém. Por esta razão estou incluindo aqui este link para que você se aprofunde no assunto caso seja do seu interesse.
Endpoints

Não há muito o que dizer sobre os endpoints de health checking do Actuator, mas acho importante que você tenha em mente dois endereços que são essenciais.
Executando todos os indicadores
Simples, você acessa o endpoint /health
Aí todos os indicadores serão executados. Não exagere no número de indicadores, pois isto irá impactar o desempenho do seu sistema.
Executando um indicador específico
É possível acessar indicadores individuais. Com isto, se quiser verificar só parte do seu sistema, basta executar o seguinte endpoint: /health/[identificador do indicador]
Se quiser acessar, por exemplo, apenas o indicador “db”, o endereço será /health/db
Quer acessar um agrupador? /health/[id do agrupador] . Um indicador no agrupador? /health/[id do agrupador]/[id do indicador] .
Aplicações

No início deste post apresentei alguns exemplos de indicadores. Agora acho importante falar com maiores detalhes sobre como costumo escrever os nossos próprios. Talvez estes usos lhe inspirem a melhorar a qualidade de serviço dos seus sistemas.
Mecanismos de persistência
Se o sistema possui qualquer mecanismo de persistência de dados, escrevo indicadores que verifiquem o sucesso das seguintes ações:
- Escrita.
- Leitura.
- Remoção.
- Acesso autorizado à informação.
- Acesso não autorizado à informação.
- Obtenção de informação existente.
- Obtenção de informação não existente.
Por persistência aqui quero dizer qualquer serviço que me permita a escrita e leitura de dados:
- Storages (S3 da AWS, Blobs da Azure, Spaces do Digital Ocean ou até mesmo sistemas de arquivos).
- Bancos de dados relacionais ou não.
- Sistemas de mensageria (RabbitMQ, SQS, ActiveMQ, etc).
Este tipo de teste é essencial em produção, costumo escrever testes que executem as ações essenciais de persistência mas não apenas isto: também o acesso a estes dados. Escrevo indicadores que validem, por exemplo, que estou obtendo erros ao tentar acessar dados que não tenho acesso ou mesmo informações não existentes.
A vantagem deste tipo de indicador é que nos ajuda a garantir parte da própria segurança do sistema.
Desempenho
Há sistemas nos quais é necessário atender requisitos muito específicos de desempenho, tal como nos exemplos abaixo:
- Tempo máximo de processamento de um endpoint.
- Número de requisições mínimo por tempo.
- Número de registros escritos por unidade de tempo.
Aqui você deve estar entendendo por que inclui como requisito de segurança as configurações de cacheamento do endpoint health. São testes normalmente caros computacionalmente, e que você não quer ver sendo executados inúmeras vezes por segundo.
Correção de bugs
Há implantações que são realizadas para corrigir bugs, certo? Que tal incluir um health indicator que possa confirmar em produção que o bug foi corrigido?
Este é um uso bem comum: você escreve o indicador que não só verifica que aquele problema foi corrigido mas também que as condições para que a ocorrência do problema não estejam presentes.
O único ponto de atenção com este tipo de indicador é que não recomendo que você inclua uma quantidade infinita deles em seu sistema, pois caso o faça com certeza terá problemas de desempenho no futuro quando os health indicators forem todos executados.
Integrações
Se o sistema tem integrações com outros sistemas (mecanismos de persistência na prática são integrações), é interessante ter indicadores que validem o acesso a estas integrações.
Você pode verificar, por exemplo, se o sistema contra o qual executa suas requisições está online. Se for possível realizar requisições reais contra estes sistemas, melhor ainda. Caso contrário, apenas saber que estão acessíveis já é informação suficiente.
Concluindo com alertas

O health checking faz parte de uma fase vital de qualquer aplicação: a pós implantação. É ele que nos possibilita verificar de verdade se o sistema realmente está operando como esperado e talvez por isto seja meu recurso favorito do Actuator.
É importante que você não confunda health checking com teste automatizado (JUnit). Apesar de terem a mesma função – verificar se um comportamento está ocorrendo tal como esperado – são executados de modo distinto e devem ser pensados de modo distinto.
Enquanto a execução de um teste automatizado não impacta de modo algum o usuário final do sistema, o health checking pode impactar negativamente (e muito) se for mal escrito. Já vi alguns erros muito tristes envolvendo health indicators como, por exemplo, a realização de compras reais em plataformas de comércio eletrônico (yeap!), gerando prejuízos significativos tanto para os stakeholders quanto para os responsáveis pela manutenção do sistema. Ou mesmo testes de carga que acabam por derrubar a plataforma.
Outro ponto importante: não conte apenas com os indicadores providos por padrão pelos módulos do Spring Boot. Eles verificam apenas funcionalidades banais como obtenção de conexões, por exemplo, mas não vão além disto. Indicadores realmente valiosos são aqueles que dizem respeito ao contexto de negócio do seu sistema.
Ainda não acabei meus posts sobre Actuator, mais estão por vir, aguardem!
Para saber mais
Configurações comuns do Spring Boot – este link da documentação do Spring Boot contém as principais chaves de configuração do framework e seus módulos (incluindo o Actuator). É uma fonte de referência muito útil. Leia com atenção as configurações relativas ao health checking do Actuator neste link.
Documentação do Actuator sobre Health Checking – a seção relativa a health checking da documentação oficial do Spring Boot.



